第28届“ACM并行程序设计原理与实践会议”(PPoPP: ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming)将于2023年2月25日-3月1日在加拿大蒙特利尔召开。PPoPP是CCF的A类会议,并行领域最顶级的国际会议之一,包括理论基础、技术、语言、编译器、运行时系统、工具和实践经验。
本次PPoPP 会议共收到131篇投稿,接受31篇, 接受率为23.6%。在本次会议中,并行处理研究所(PPI)的一篇论文被录用。这是继2017、2019年后,实验室在并发索引结构领域第3次在PPoPP上发表论文。论文信息如下:Weihua Zhang, Chuanlei Zhao, Lu Peng, Yuzhe Lin, Fengzhe Zhang, Yunping Lu. Boosting Performance and QoS for Concurrent GPU B+trees by Combining-based Synchronization.The 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP 2023), Montreal, Canada. 2023.
并发B+树是基础的数据结构,是数据库、文件系统等存储系统最核心的索引结构之一,例如XFS, PostgreSQL。随着数据请求的规模呈指数级增长,系统正面临着巨大的性能压力。GPU在加速并发B+树性能方面展现了它的潜力。当大规模并发请求被处理时,请求之间的潜在的冲突需要被检测和解决。先前的方法通过基于锁或基于软件事务存储器(STM)的方法来保证并发GPU B+树的正确性。然而,这些方法使请求处理逻辑复杂化,增加了内存访问量并引发执行路径分叉(如图1所示),从而导致了性能下降和响应时间波动的增加(如图2而所示)。此外,可线性化是保证并发请求处理正确定和公平性的重要原则,然而此前的方法并不提供并发请求之间的线性化。

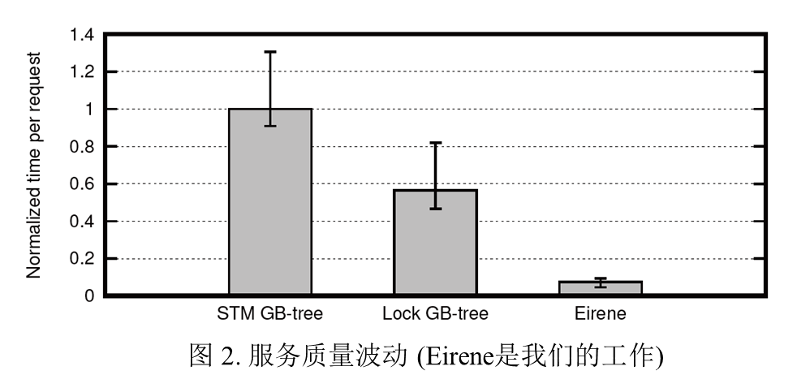
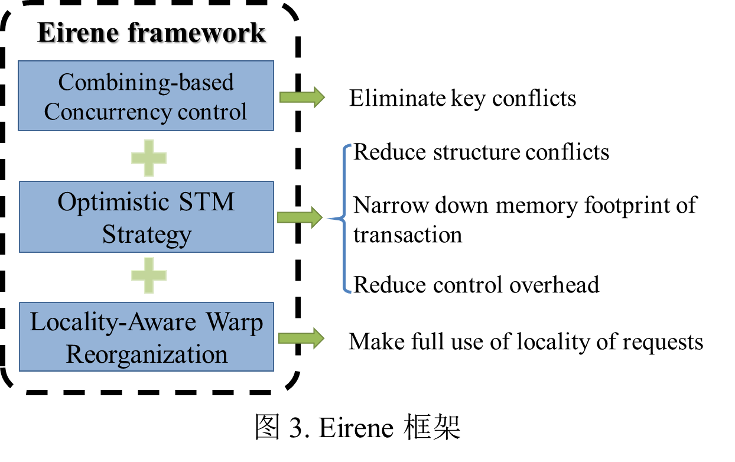
论文提出了一个为GPU B+树设计的Combining-based并发控制框架(如图3所示),简称Eirene,以减少冲突检测和解决的开销并保证并发请求可线性化。Eirene 框架使用 Combining-based 同步方法来组合和执行请求,以消除键冲突并保证线性化。该方法结合具有相同键的请求,构建它们的依赖关系以决定后续执行的请求,并确定其返回值。每个相同键的请求只有一个会被执行,从而完全消除键冲突。此后,Eirene采用乐观的STM策略来减少结构冲突。查询和更新请求被分发到不同的GPU内核。对于更新内核,只在请求重试次数达到阈值时才会触发STM保护。最后,Eirene执行局部性感知的Warp重组优化方法,以改善GPU内存行为,并通过利用请求之间的局部性来进一步减少冲突。实验评估表明,Eirene 能达到每秒24亿的并发读写吞吐量,并能保证并发请求之间的可线性化。与最先进的并发GPU B+树(发表于PPoPP’19)相比,Eirene实现了7倍的吞吐量提升,并将响应时间波动从36%降低到5%。
该工作是PPI 继 Eunomia[PPoPP’17]、 Harmonia[PPoPP’19] 之后,在并发索引结构加速方向的又一领先性成果。