2024年IEEE/ACM国际代码生成与优化研讨会”(IEEE/ACM International Symposium on Code Generation and Optimization)将于2024年3月2日到3月6日在英国爱丁堡召开。CGO是代码生成与优化领域的顶级国际会议之一,CCF分类为B类。
本次会议中,并行处理研究所(PPI)的一篇论文在CGO 2024首轮提交周期中(共两轮提交周期)被接收,论文信息如下:
Jinhu Jiang, Zhongjun Zhou, Chaoyi Liang, Rongchao Dong, Zhaohui Yang, Wenwen Wang, Pen-Chung Yew, Weihua Zhang. A System-Level Dynamic Binary Translator Using Automatically-Learned Translation Rules. To Appear in IEEE/ACM International Symposium on Code Generation and Optimization (CGO 2024)
系统级仿真器被广泛用于系统软件的设计、调试和评估中。它们的工作原理是提供一个系统级虚拟机,支持运行与宿主机相同或不同指令集的操作系统以及其上的应用。对于这样的系统级仿真,动态二进制翻译(DBT)是其核心技术之一。基于学习规则的动态二进制翻译方法通过从编译器中学习具有编译优化信息的不同指令集之间的翻译规则,提高二进制翻译过程中的翻译代码质量,从而提升DBT的性能。但是,已有方法只用于用户级DBT,而不支持系统级仿真。
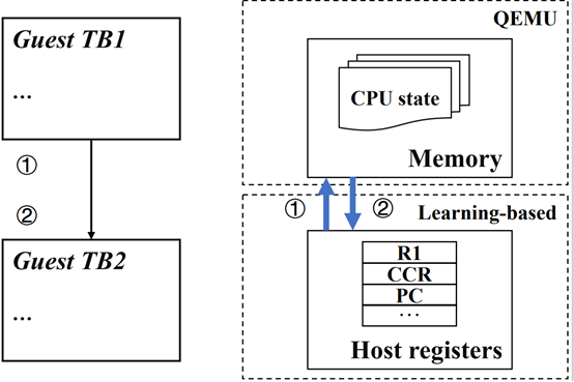
论文首先基于QEMU实现了一个基于学习规则的系统级仿真器,并针对基于学习规则的DBT方法在系统级仿真中的性能瓶颈进行了分析。基于学习规则的DBT方法使用宿主机寄存器来维护GUEST处理器的系统状态,而原始QEMU则使用内存维护GUEST处理器的系统状态。在系统级仿真中,由于基于学习规则的方法无法完成所有指令的翻译(覆盖率94.1%),对于一些特权指令、系统态内存行为与异常处理等需要基于QEMU机制完成。在这种过程中,两种DBT方法会引起GUEST处理器的系统状态的同步操作,从而导致较大的同步开销。
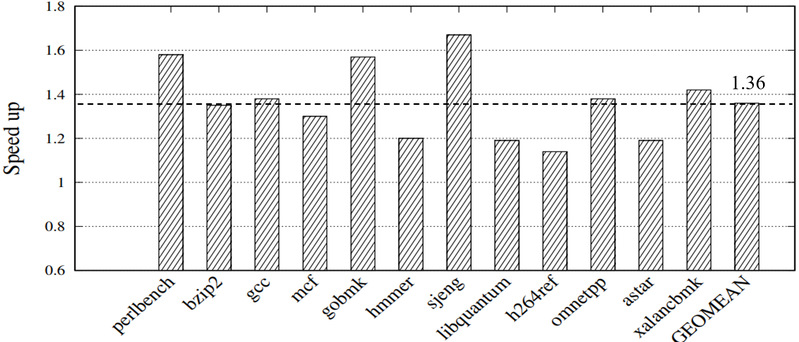
论文针对此类同步操作提出了三种优化策略,三种优化分别从降低同步开销、减少同步次数以及指令调度等方面对同步操作进行了优化,并显著提高了仿真器性能。
1、降低同步开销优化:宿主机的一个寄存器可能同时保存多个系统状态,这些系统状态被QEMU分开保存在内存中 (如条件码),对此类系统状态同步中,需要对宿主机寄存器状态进行拆解,从而导致较大的同步开销。因此在进行同步操作时,如果对应的状态在切换过程中不会被使用,则将此类“一对多”的系统状态作为整体进行备份,仅当QEMU需要访问它们时再对其进行解析,从而优化单次同步的开销。
2、减少同步次数优化:初始算法中,对每次切换都会做系统状态保存和恢复,但对于连续的切换(如连续memory访问)或者系统状态在后继操作中会被修改,则会导致冗余的状态保存和切换,从而影响性能。针对这些情况,我们将连续指令引起的状态保持和恢复合并,同时通过简单的数据流分析,对移除后继状态被修改状态的恢复,从而移除不必要的同步开销。
3、指令调度:在Guest指令执行过程中,如果define指令和对应use指令中间有其它需要进行系统状态切换的情况发生,在define指令后需要进行状态保存,use指令前需要进行恢复。这种方式会引入大量的系统同步,如果define指令涉及到的系统状态改变不影响其与user指令间其它指令的行为,通过将define指令调度到user指令前可以有效避免不必要的状态同步。
实验结果显示,基于学习规则的方法与QEMU 6.1相比,可在SPEC CINT 2006基准测试集上实现平均36%的性能提升;在memcached、sqlite等真实应用测试中,该设计可实现平均15%的性能提升。