项目背景:
动态二进制翻译在系统模拟、代码迁移等领域承担着至关重要的角色。动态二进制翻译将源指令架构的二进制代码直接翻译转化为目标指令架构的二进制代码,并在目标机器上进行执行。传统的动态二进制翻译方法需要耗费大量的精力来构建两种指令集之间的翻译规则,并且需要对原指令集架构与目标指令集架构相当熟悉。基于中间表达语言(Intermediate Representation, IR)进行的二进制翻译,往往由于生成IR以及翻译IR带来的开销,以及忽略了目标架构的一些特性而导致生成的代码性能降低。
项目成果:
本项目使用新型的基于自动学习的动态二进制翻译方法,无需对指令集架构有相当的熟悉程度,可以生成任意两种指令集之间的翻译规则,并结合编译器对指令集架构的优化,结合源指令架构与目标指令架构的特性,生成高效的翻译规则。如图1所示,对于任意的指令集架构,通过将源代码编译分别成源指令架构与目标指令集架构的二进制码,通过以下方法进行自动学习生成翻译规则:即对于同一行的源代码来说,两个架构的编译生成二进制码尽管指令不同,但在语义上完全相等。这样做的另一个好处在于,我们可以使用优化等级较高的优化选项(例如-O2)对源代码进行自动学习,从而生成质量更高的翻译规则;而更高质量的翻译规则将会大大提升生成代码的质量。实验结果证明,我们的性能提高了1.19倍,具体参考论文[1]。
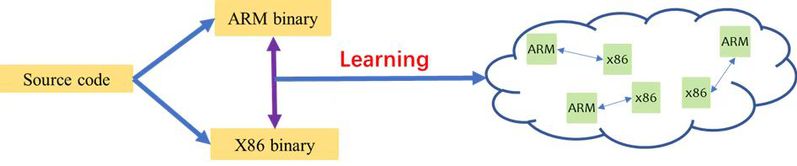
图1
然而基于自动学习的方法仍然有些缺陷,首先对于某些稀有指令,许多程序没有或者出现次数很少,这为自动学习带来了一定的困难,因为自动学习只能够学习程序中出现的指令;其次尽管我们扩大的学习的范围以及学习更多的程序,我们发现学习的效率降低了,学到的新的翻译规则越来越少,并且仍然不能够完全覆盖整个指令集。如图2数据所示,在扩大了学习范围后,代码的覆盖率仍然只有69.7%。为了能够覆盖所有的指令,本项目通过使用参数化翻译规则方法,泛化现有翻译规则的适用范围,从而降低自动学习的成本,并最终实现了指令集的全覆盖。参数化方法基于以下观察:首先我们发现指令集指令通常可以被分为几种类型,例如算术逻辑运算指令、访存指令等等;而通常这些指令具有相似的操作码格式,例如访存指令总是有一个寄存器与一个内存地址组成;这使得这些指令可以转变为一种统一的表达形式,并且一旦有了统一的参数化操作码以及操作数,新的翻译规则将可以适用于所有的这一类指令,从而使翻译规则的使用范围大大提高。基于此我们将所有的翻译规则进行参数化,通过分类,将翻译规则中的同一类指令转变为参数化表达形式,如图3是参数化翻译规则以及翻译规则应用的过程,在参数化阶段通过一些指令约束的检查,我们生成了参数化的翻译规则。在执行过程中,解析约束检查并且实例化翻译规则从而将翻译规则应用与所有指令。实验结果证明,如图4,我们对指令集的覆盖率达到了95.5%,并且性能提高了1.24倍,具体参考论文[2]。
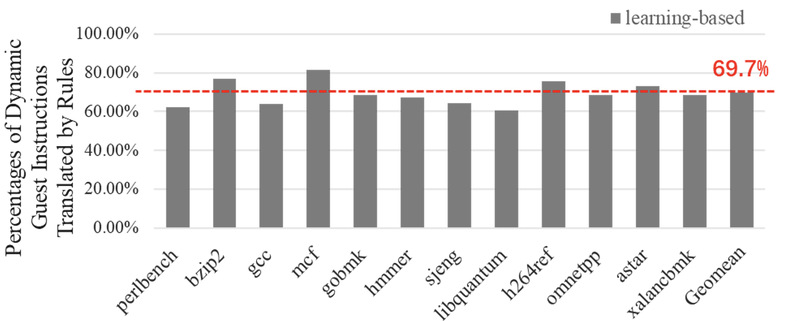
图2

图3
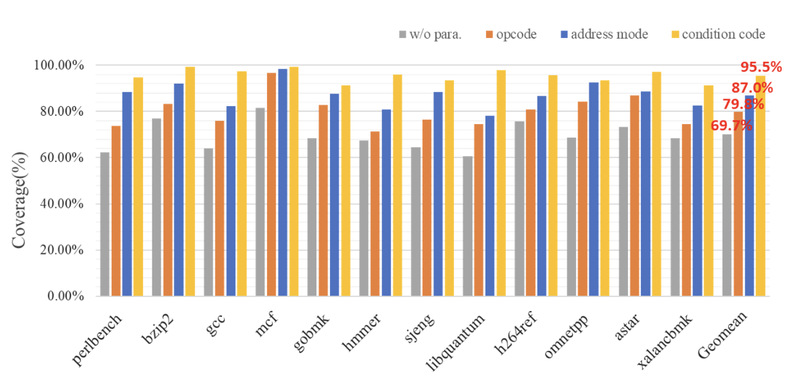
图4
基于学习的动态二进制翻译方法现已开源,详见链接[3]。
[1] Changheng Song, Wenwen Wang, Pen-Chung Yew, Antonia Zhai, Weihua Zhang. Unleashing the power of learning: an enhanced learning-based approach for dynamic binary translation[C]//2019 USENIX Annual Technical Conference (USENIX ATC 19). 2019: 77-90.
[2] Jiang J , Dong R , Zhou Z , et al. More with Less – Deriving More Translation Rules with Less Training Data for DBTs Using Parameterization[C]// 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 0.
[3] 开源链接:https://github.com/fudan-ppi/Rule_based_DBT