项目背景:
B+树是最重要的数据结构之一,在各个领域得到了广泛的应用。随着并发查询和存储数据规模的增加,设计高效的B+树结构变得至关重要。由于计算资源丰富,SIMD体系结构为B+树提供了实现高查询吞吐量的潜在机会。然而,由于资源利用率低和内存性能差,以前的方法无法获得令人满意的性能结果。
项目成果:
我们首先确定了B+树和SIMD体系结构之间的差距。并发B+树查询涉及许多全局内存访问和不同的差异,这与SIMD体系结构特征不匹配。基于这一观察,我们提出了Harmonia,一种新的B+树结构来弥补这些差距。Harmonia 结构设计如图1.所示。在Harmonia中,B+树结构分为关键区域和子区域。关键区域按宽度优先顺序存储节点及其关键点。子区域被组织为一个前缀和数组,它只在关键区域存储每个节点的第一个子索引。由于前缀和子区域较小,并且子索引可以通过索引计算来检索,因此大部分子索引可以存储在片上缓存中,从而实现良好的缓存局部性。为了提高效率,Harmonia还包括两个优化:部分排序聚合(PSA)和缩小线程组遍历(NTG),分别如图2. 图3 所示。 对于PSA,我们在发出查询之前在时间窗口中对查询进行排序。由于相邻的排序查询更有可能共享相同的树遍历路径,因此当在SIMD单元中处理多个相邻查询时,合并内存访问的机会会增加。对于NTG,我们减少了每个查询的线程数,以避免无用的比较。当每个查询的线程组缩小时,可以将更多查询合并到一个SIMD单元中,这可能会增加执行差异。为了缓解查询组合带来的执行分歧问题,我们设计了一个模型来决定如何缩小查询的线程组, 进而缓解内存和执行差异,提高资源利用率。我们对Harmonia 在CPU和GPU平台进行了评估。对28核INTEL CPU的评估表明,Harmonia每秒可以实现2.07亿次查询,比基于CPU的HB+Tree(最近最先进的B+tree设计方案)快约1.7倍。在Volta TITAN V GPU上,它每秒可以实现36亿次查询,比基于GPU的HB+Tree快3.4倍。具体参考论文[2]。
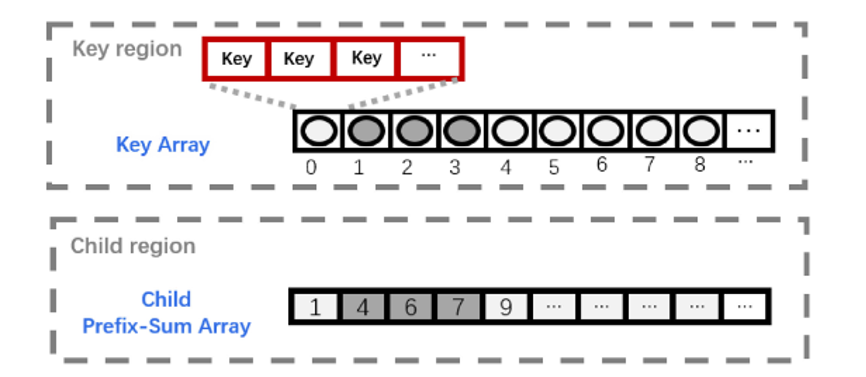
图 1. Harmonia 结构
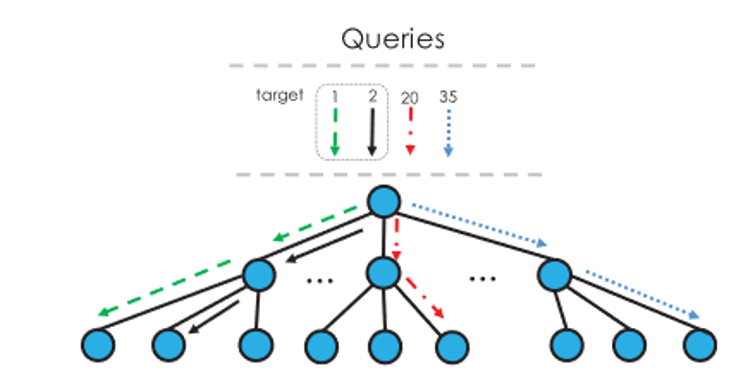
图 2. PSA 搜索方法
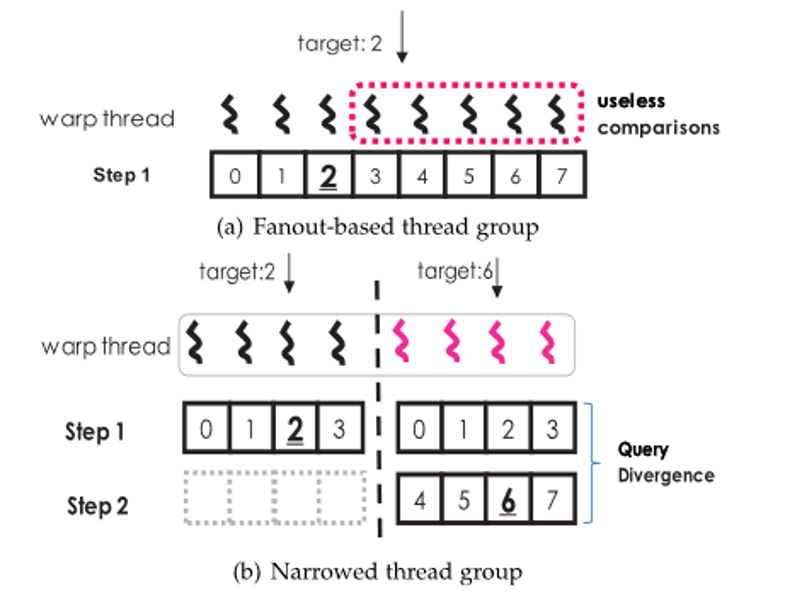
图 3. NTG 搜索方法
发表论文:
[1] Yan Z, Lin Y, Peng L, Zhang W. ACM, 2019. Harmonia: a high throughput B+tree for GPUs[C]//Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming. , 2019Washington District of Columbia: : 133–144.
[2] Zhang W, Yan Z, Lin Y, Zhao C, Peng L. A high throughput b+tree for SIMD architectures[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 31(3): 707–720.